Latent Wasserstein Adversarial Imitation Learning
Siqi Yang1 , Kai Yan1 , Alexander G. Schwing1 , Yu-Xiong Wang1
1 University of Illinois Urbana-Champaign (UIUC)
ICLR 2026
PDF | Code
Abstract
Traditional distance metrics fail to capture environment dynamics in Wasserstein AIL;
we solve this by computing the Wasserstein distance in a dynamics-aware latent space.
Full Abstract
Imitation Learning (IL) enables agents to mimic expert behavior by learning from demonstrations. However, traditional IL methods require large amounts of medium-to-high-quality demonstrations as well as actions of expert demonstrations, both of which are often unavailable. To reduce this need, we propose Latent Wasserstein Adversarial Imitation Learning (LWAIL), a novel adversarial imitation learning framework that focuses on state-only distribution matching. It benefits from the Wasserstein distance computed in a dynamics-aware latent space. This dynamics-aware latent space differs from prior work and is obtained via a pre-training stage, where we train the Intention Conditioned Value Function (ICVF) to capture a dynamics-aware structure of the state space using a small set of randomly generated state-only data. We show that this enhances the policy's understanding of state transitions, enabling the learning process to use only one or a few state-only expert episodes to achieve expert-level performance. Through experiments on multiple MuJoCo environments, we demonstrate that our method outperforms prior Wasserstein-based IL methods and prior adversarial IL methods, achieving better results across various tasks.Why the Distance Metric Fails
Many prior Wasserstein IL [1] works that employ the Kantorovich-Rubinstein (KR) dual overlook an important issue: the distance metric between individual states is rather simplistic. For this, the Euclidean distance is common. However, it fails to capture the environment’s dynamics. For example, a state might be physically close to an expert state in Euclidean space, but unreachable due to an obstacle, making it a poor metric for the learning process.
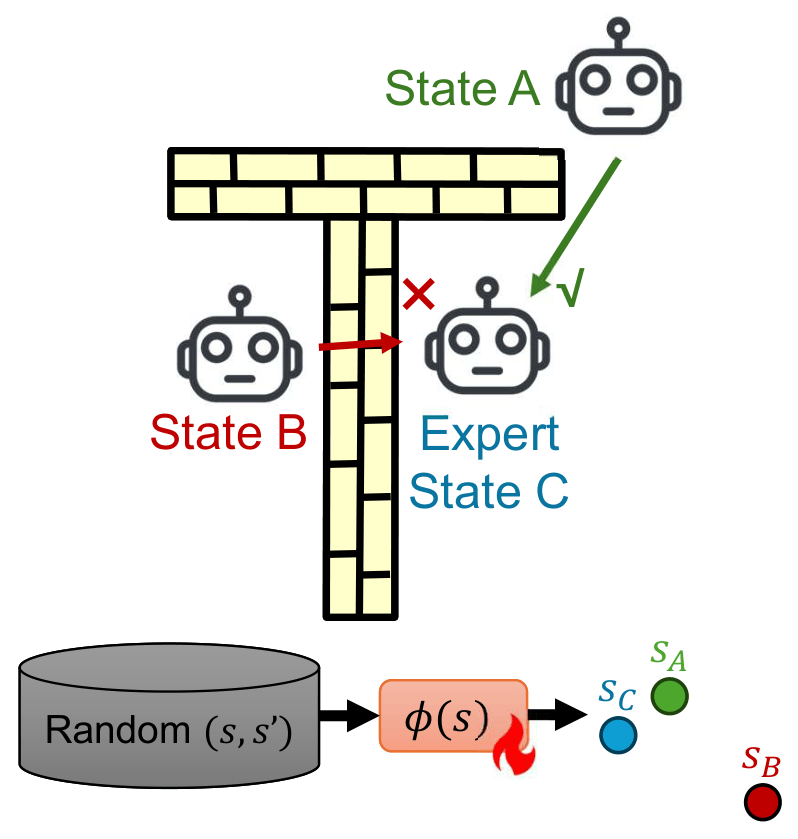
Illustration of a case where the Euclidean distance between states is not a good metric (State B is closer to Expert State C in Euclidean distance, but actually State A is closer to Expert State C in real dynamic world).
We propose a two-stage process:
- Pre-training stage: We leverage a small (1% of online rollouts) number of unstructured, low-quality (e.g., random) state-only data to train an Intention-Conditioned Value Function [2]. The resulting embedding captures a rich, dynamics-aware notion of reachability between states.
- Imitation stage: We freeze this ICVF embedding and use the Euclidean distance in this new latent space as the cost function within a standard Wasserstein AIL framework.
In the adversarial imitation learning stage, we optimize the following objective:
Performance
We validate our approach on pointmaze, antmaze, and challenging locomotion tasks in the MuJoCo environment from the D4RL benchmark, achieving strong results using only a single trajectory of state-based expert data. The results show that the latent space grasps the transition dynamics much better than the vanilla Euclidean distance.
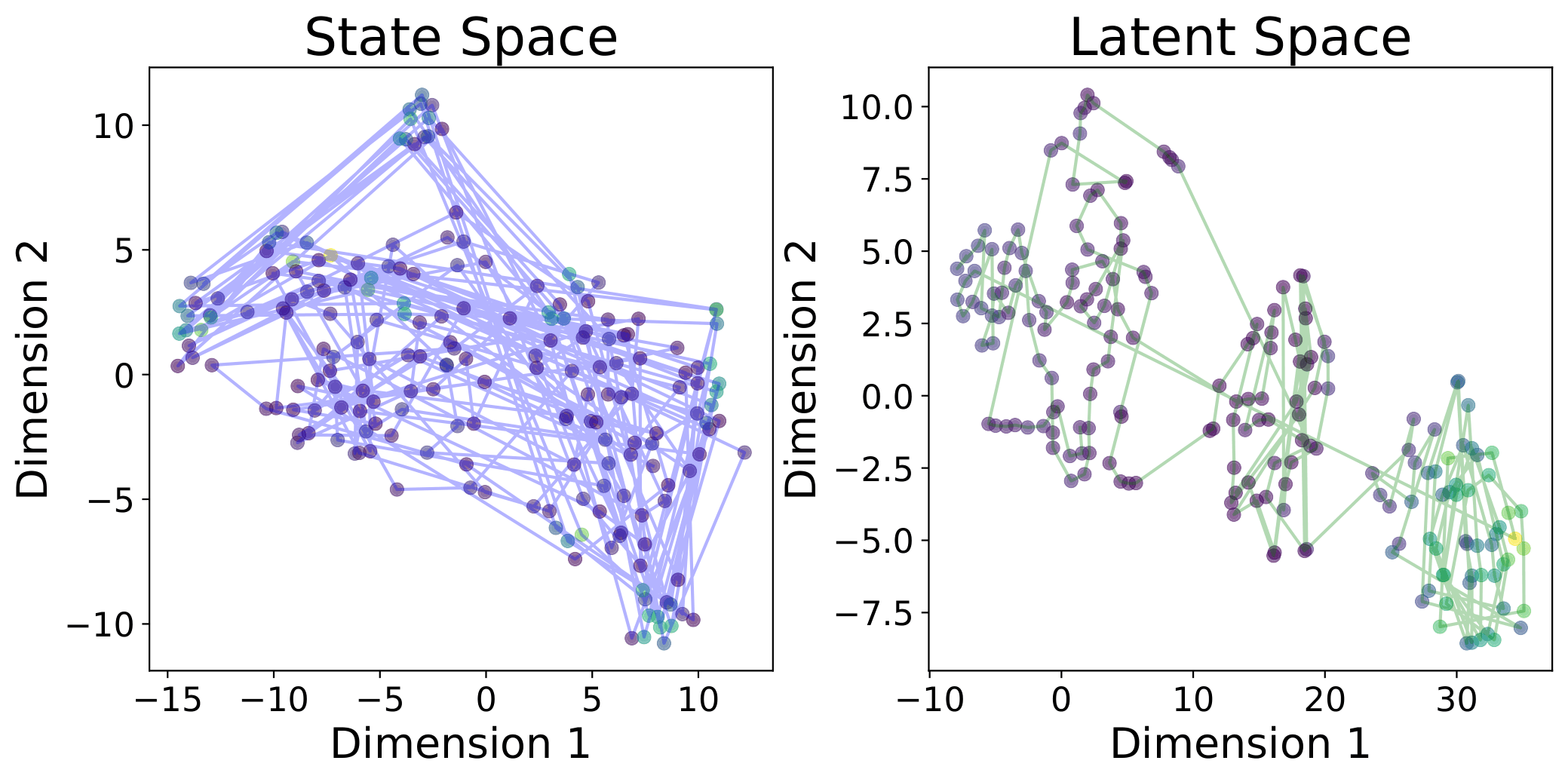
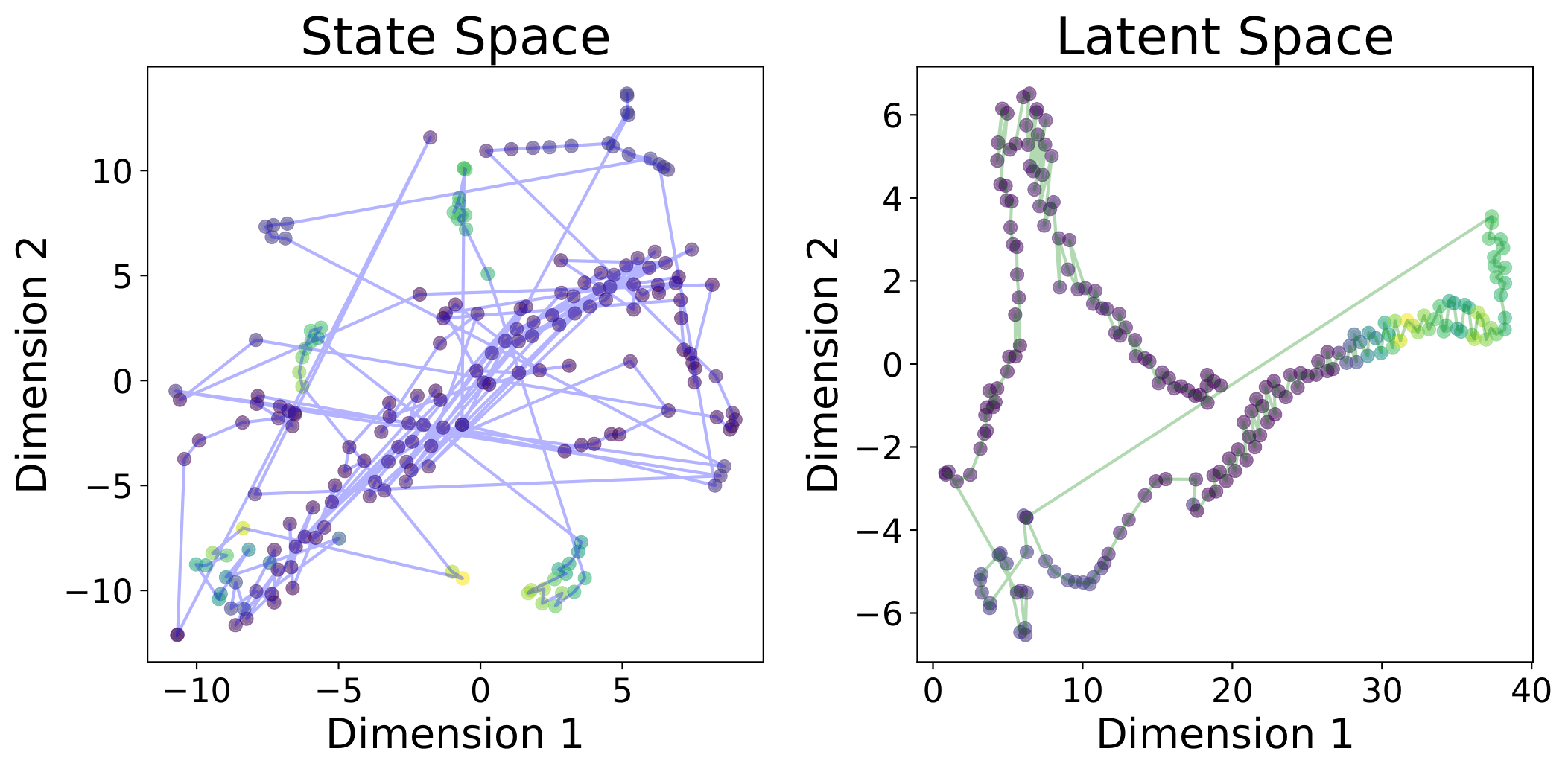
tsne_halfcheetah tsne_walker
t-SNE visualizations in the original state space and the embedding latent space on HalfCheetah and Walker2d. The color of the points represents the ground-truth reward of the state (greener is higher). States connected by lines are adjacent in the trajectory. The ICVF-trained embedding provides a more dynamics-aware metric.
MuJoCo Environments (1 Expert Trajectory)
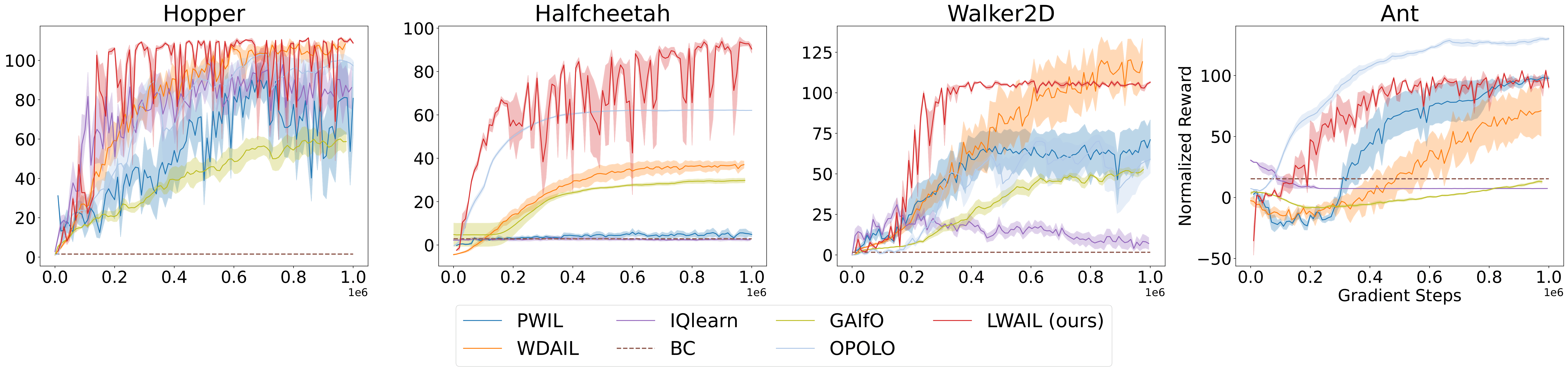
Normalized Rewards (Higher is Better)
References
[1] Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In ICML, 2017.
[2] Dibya Ghosh, Chethan Anand Bhateja, and Sergey Levine. Reinforcement learning from passive data via latent intentions. In ICML, 2023.